카프카(Kafka)?
Apache Kafka is a distributed data streaming platform that can publish, subscribe to, store, and process streams of records in real time. It is designed to handle data streams from multiple sources and deliver them to multiple consumers. In short, it moves massive amounts of data—not just from point A to B, but from points A to Z and anywhere else you need, all at the same time.
카프카는 여러 소스들에서 해당 데이터가 필요한 다양한지점들에게 대용량 데이터를 실시간으로 이동시킬 수 있는 플랫폼이라고 할 수 있다.
1. 카프카 토픽(Topic)?
- 하나의 토픽은 여러개의 파티션으로 구성될 수 있다.
- 데이터는 끝에서부터 큐형식으로 0번부터 쌓이게 된다.
- Consumer가 데이터를 가져가도 데이터는 삭제되지 않는다.

- 새로운 파티션이 추가된 후, 데이터가 추가될때 키카 null이고 기본 파티셔너 사용하게 되는 경우 -> 아래와 같이 라운드 로빈으로 할당되기 때문에 그림 1과 같이 4번 데이터는 partition #1, 5번 데이터는 partiion #0으로 할당되게 된다.
- 파티션을 추가하게되면 consume 개수를 늘려 분산처리 시킬 수 있다.
- 파티션 데이터는 저장 시간과 용량을 지정하여 관리 할 수 있다.

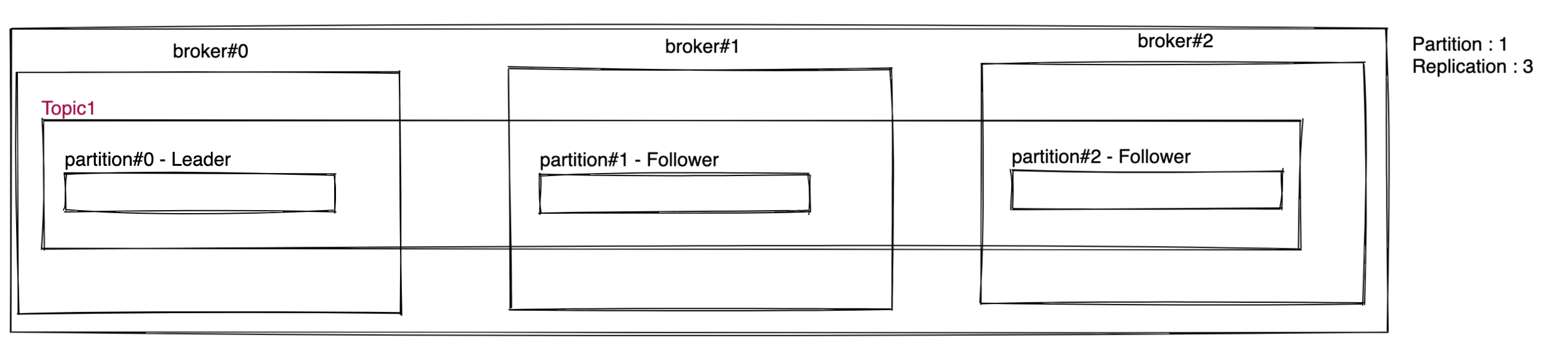
2. 카프카 브로커(Broker)?
- 카프카가 설치되어있는 서버 단위이다.
- 보통 3개이상의 브로커를 구성하도록 권장.
(브로커가 한대라면 문제가 생겼을때 복구 불가하기 때문)
- 원본 파티션을 Leader, 원본을 복제한 다른 파티션을 Follower라고 부른다.
(원본 브로커에 이슈가 생기더라도, 다른 브로커가 리더 파티션 역할을 승계하게 된다.)
- 프로듀서에는 ack 라는 상세 옵션이 있어, 고가용성을 유지 할 수 있다.
=> ack=all하게 되면, 프로듀서가 publish한뒤, Leader파티션에서 정상적으로 저장되었는지 응답을 받을 뿐 아니라, Follower 파티션으로 ISR(In-Sync-Replication)이 잘 이루어 졌는지 확인하는 절차까지 받아 데이터 유실이 없게 할 수 있다. (*그러나 속도다 ack=0이나 ack=1보다 현저히 느리다.)
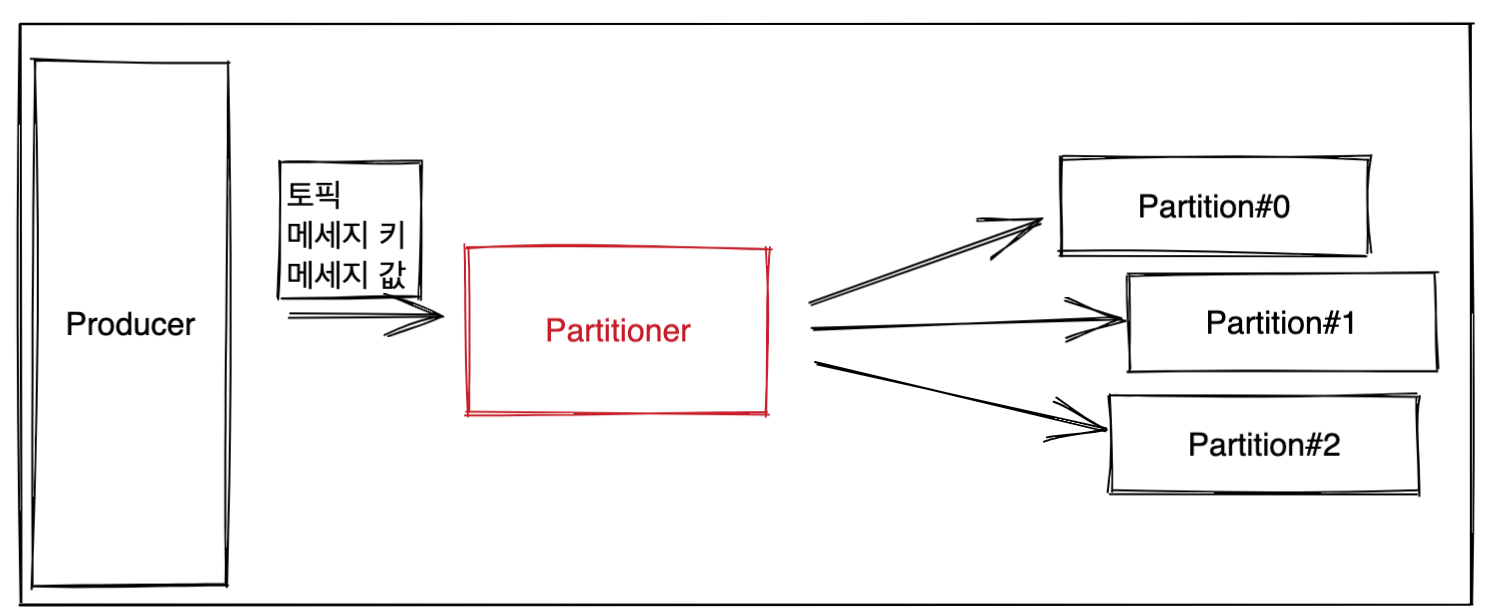
3. 파티셔너(Partitioner)?
- 어떤 파티션으로 보낼지 결정한다.
- 데이터 레코드에 포함된 메세지 키 또는 값에 따라 어떤 파티션으로 보내지는지가 결정되게 된다.
- if 특정키가 설정이 되는경우 -> 해쉬값을 기준으로 어떤 파티션으로 보내지는지가 결정된다.
- else -> UniformStickyPartitioner로 설정되며, round-robin 방식으로 적절히 분배된다.
4. Consumer Lag?
- (Producer가 마지막으로 넣은 offset) - (Consumer가 마지막으로 읽은 offset)을 Consumer lag이라고 한다.
- 여러 파티션이 존재 할 경우, consumer lag은 여러개가 존재할 수 있다.
- 그 중 높은 숫자의 lag을 records-lag-max라고 한다.
- Consumer Lag을 모니터링함으로써, Consumer의 성능을 확인하고 이슈를 방지 할 수 있으므로 모니터링하는것이 중요하다.
